In my time with Oracle, the company shifted it’s course from OCI-Classic to onboarding all new customers, and migrating current customers to OCI. This would provide some challenges for current customers as they would require an exercise in taking inventory of their current cloud resources. This would help in capacity planning for their future in Oracle’s cloud. Some customers kept up to date spreadsheets of all their current services in OCI-C, while others were seeking help with a more automated approach at mapping their current OCI-C resources.
The Situation
I was assigned to help a customer with their capacity planning for migration. They were in need of some information that Oracle couldn’t provide (as it was beyond a security boundary) and other information that could be provided programmatically using the OPC API. I was determined to give this customer the most information that could be provided in an automated fashion. They were specifically interested in their IaaS compute instances and collecting metadata information about them. I figured a simple CLI application could do the trick.
The Solution
I was able to cobble together a NodeJS application that could be configured with endpoint information, check the user’s credentials and pull all the necessary information down from the API. Once that was done, we could introspect it for the specific information we were looking for and write it to a simple CSV file.
If you’re on OCI-C and need to collect your own IaaS instance information, hopefully this tool can help you too!
I bought a new computer a while back. I do a lot of file moving/manipulation/cleanup on my home PC because I’m an avid Plex user. For these tasks I simply use .bat or .cmd files and the Windows task scheduler. It’s quite a simple solution and generally runs like clock work. Until it doesn’t and you can’t understand why.
First Attempt
After some internet searches I stumbled across the Tweaking.com windows repair program that offered fixes and had quite a few recommendations. With my fingers crossed I installed the app and tried it out. It did not fix my Windows task scheduler problem. But I did end up buying a license for it because it’s an amazing piece of software that does a lot of optimizations.
Coding Your Own
Time to think about rolling my own. What do I need this thing to do?
Always be running
Run .bat or .cmd files on an interval
So for #1 something always running, I immediately think Windows service. I’ve long used TopShelf for this sort of thing. It’s highly configurable and easy to use. For #2 I considered using Quartz.NET, but I thought it would be overkill. I just rolled my own interval and tracking code. I specifically needed to run .bat and .cmd files, for this I found a project called MedallionShell. It runs commands in threads within your application. You could use it for parallelism, but I decided not to introduce that complexity into my simple use case.
Learning
This project brought some fun learning aspects. I was able to implement builds using Cake builds for C# and also automate my builds using AppVeyor. With all of this in place it will build my code and put a release on GitHub for me. Pretty nifty! Even got some badges working on the project home page.
Conclusion
I learned a lot doing this simple little project and had a lot of fun doing it. I wish I knew why the Windows task scheduler doesn’t run my tasks. I guess as long as it runs all of the other important ones, I can be good with that.
I have been doing a lot of research into the MEAN stack as of late in hopes of possibly using in on my next project. First I wanted to see if using TypeScript was viable, because I come from a .NET background and strong types help me find problems at compile time. Then I wanted to see if I could get some sort of debugging experience. I remember the good ol’ days of Classic ASP scripting and having to debug write everything so I could get a picture of what was happening.
Editor(s)
So many to choose from in this department. Personally I chose WebStorm because it afforded me that debugging experience I was looking for in the IDE. SublimeText and VS Code are excellent options as well, but like I said… Debugging.
Getting Lessons
My first round of searches brought me to an excellent video tutorial by Brad Traversy on MEAN Stack Front To Back. It’s a series in which you’ll use ES6 to create a MEAN stack application that does some simple authentication. It’s a great series, I highly suggest watching it and checking out the code here. It uses ES6 and like I said, I’m looking for TypeScript.
My mission was to combine the two projects to make one MEAN application with a TypeScript and test driven backend and an Angular2 front end. I was able to take the lessons learned about TypeScript, Grunt, Mocha and Chai and apply it to the meanauthapp created in Brad’s videos. It makes for very easy and type-safe development with NodeJS. Big thanks to both Brian and Brad for their work!
Isn’t the whole point of durable, reliable messaging that we can re-queue a message for processing? – Me
The Background
I recently got involved in a project using Azure Service Bus. The premise was simple, run service bus queue messages through a WebJob durably and reliably. For this project I ended up using the Topics feature for a publish/subscribe model. I got the project up and running fairly quickly thanks to the WebJobs SDK. By default the message will be attempted 10 times and then automatically sent to the DeadLetter queue. So to test this, I throw an exception during message processing and sure enough it goes as expected. I now have a message in the DeadLetter queue. In the Azure Management Portal I can see the message exists where it’s supposed to. As of the writing of this article the Azure Management Portal only supports changing the properties of Topics and not managing the messages in them.
Supplemental Software
What I need is a piece of software that will let me manage the messages in the queue. I could write it myself, but this seems like a task there would be a tool for.
My first round of searches dug up Service Bus Explorer. It’s a free Service Bus management tool. It looks like a great piece of well thought out management software, but I was unable to get the DeadLetter Repair and Resubmit Message to work properly for me.
My next round of digging brought me to Azure Management Studio. This is a paid piece of management software that helps manage more than just your Service Bus. This tool was able to properly copy and re-submit the queue message back to it’s Topic of origin. Success!
Side Note
If Domain Driven Design and Message Queues are highly important to your system, you may want to check out NServiceBus. I just needed some bolt-on queues for middleware which is why I decided to just tackle queueing on my own.
Now after searching NuGet I saw that there is a C# WooCommerce library out there all ready written called WooCommerce.NET. This isn’t going to work for me because I will need the ability to gain access to custom Order fields.
So I decided to just use my favorite REST client RestSharp to contact a fairly simple REST API for WooCommerce. But I was running into a strange authentication issue and being denied authentication with a 401 status code.
Now, first a disclaimer… DO NOT USE HTTP FOR WooCommerce IN A PRODUCTION ENVIRONMENT!
Ok, but I need to do some testing in a local environmnet so I can see that my code is working properly. Reading the WooCommerce documentation for authentication, which can be found here, it clearly states:
The OAuth parameters must be added as query string parameters and not included in the Authorization header. This is because there is no reliable cross-platform way to get the raw request headers in WordPress.
RestClient client = new RestClient(baseUrl); RestRequest request = new RestRequest(Method.GET); var authenticator = OAuth1Authenticator.ForRequestToken(consumerKey, consumerSecret); authenticator.ParameterHandling = OAuthParameterHandling.UrlOrPostParameters; authenticator.Authenticate(client, request);
var requestUri = client.BuildUri(request); var actual = HttpUtility.ParseQueryString(requestUri.Query).AllKeys.ToList();
Assert.IsTrue(actual.SequenceEqual(expected)); }
The above Authenticate method will do all the work and add all the parameters I need.
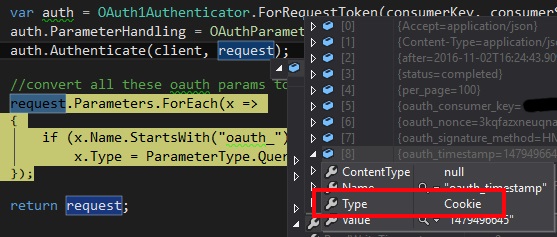
But wait… Something’s not right here. In the debugger it shows me that the parameters on the request are being added as cookes:
Strange, but ok. So I decided to make an extension method that does all the authentication, gets all the parameters added to the request, and then converts them to QueryString parameters.
//convert all these oauth params from cookie to querystring request.Parameters.ForEach(x => { if (x.Name.StartsWith("oauth_")) x.Type = ParameterType.QueryString; });
return request; } }
So the code to build a request now looks something like this.
1 2 3 4
var client = new RestClient("http://example.com/api/v1"); var request = new RestRequest("/path/to/resource"); request.BuildOAuth1QueryString(client, "{consumer_key}", "{consumer_secret}"); var response = client.Execute(request);
I can not stress enough to not communicate over HTTP in production. In production, you should be using HTTPS. In that case you can use HTTP Basic Authentication. Then you will no longer need the BuildOAuth1QueryString extension method, you would simply add the Basic Authentication to the client like so:
1 2
//Basic over Https client.Authenticator = new HttpBasicAuthenticator("{consumer_key}", "{consumer_secret}");
Every day in the ever changing world of technology and development, I try to do some reading to keep up with the world around me. I have worked in places with small teams and big teams, but my current situation puts me as the only person with development skills in my current company. It’s really important in this situation, not to lose touch with the world of development around you. This feed has kept me up to date with new tech and also taught me even more about tech I all ready thought I knew.
I’ve been curating this list of blog feeds since I became a developer a long time ago, so many of them may be out-dated. Still, there are always great articles popping up for me to read and dabble in the tech if I have the time. Personally I use Feedly for my RSS reader, but the file should easily import into your favorite RSS reader.
I was talking to a friend the other day about what you need to know to be an effective developer. We touched on topics like source control, people skills, presentation skills and a ton of other skills that are inherent things that are need to know. Other things could include frameworks, good blog sites, or how to get what you’re asking for from your boss. After a while we got into the code aspect of being a developer. Where do you start? What is a waste of time to learn? When should I know what? Well, I certainly don’t know the best way but I’ll share the order that worked for me.
Let’s just start basic. The first thing you should know about developing for whatever it is you want to write code for is the syntax of the language you’ll be using. Start simple, think “Hello World”.
Once you have an understanding of the 4 pillars in my opinion your next stop should be learning the SOLID principles
Single responsibility principle
Open/closed principle
Liskov substitution principle
Interface substitution principle
Once you’ve gotten to principles you can start to make more maintainable code in larger projects.
Finally, once you’ve gotten those down it’d be best to look into the Gang of Four Design Patterns. These are proven patterns for enterprise scale production systems. If you have a good understanding of the problem you’re trying to solve, there’s a good chance a combination of these patterns will help you solve it.
All of this being said, there are problems you come across time and again as a developer. One of the biggest ones I face often is that of cross cutting concerns. I have this thing that does one thing, but now needs to do another. For example, you have data going into a database and you’d like to audit who put the record in with some sort of logging. In this case there are many solutions, and you could even write your own using all those spiffy patterns. Or in my case I found a great library called MediatR that implements a nice architecture solving that problem for me. Sometimes with the right amount of digging you’ll find a good library that solves the recurring problems.
Update
It is almost imperative now to know about cloud architecture for hightly available and scalable applications. I had the pleasure of reconnecting with a former colleague of mine who so happens to be a cloud architect at Microsoft. He pointed me toward his GitHub for some guidance on Microsoft Azure cloud architecture. You can see the repository on his GitHub here.
I’ve been working with a lot of NodeJS stuff lately in my off time using things like Bower, Grunt, Gulp, etc… It’s been a nice break from my usual .NET stuff. It’s been a long while since I had my site up, running and full functional with a blog and everything. I’m not sure how much I’ll use it, but I used to put a lot of time and energy into blog posts. Maybe I’ll see if I can recover those old posts somehow. But for now I’m up and running with GitHub Pages and Hexo.
I was able to get some, but not all of my old posts back. It took a lot of digging and code re-formatting but it was worth it. Took some time learning EJS and Hexo template stuff, but the site is looking nice.
Much like everyone else, I started my career as a coder. Rob Conery from Tekpub has a great series on going from coder to developer here. Being the coder has it’s up sides, low responsibilities being one of them. If you just like to do what you do and go home, then there is no need to move up for you here. This usually consists of taking strict written or verbal requirements and turning them into a bit of code. This person is usually in charge of testing too. You usually are under at least one person who guides you a lot. But if you aspire to do more, you will most likely want to become a developer.
The Developer
The developer has a lot more decision making power when it comes to both requirements and system architecture. In most scenarios, a discovery phase of a project is done and then all of that is in turn made into functional requirements. The developer can be called upon to both try to make requirements from the discovery documents or review functional requirements for refinement. The developer also has a bit more reign when it comes to speaking to clients and making bigger decisions in system architecture and implementation.
The Architect
The architect has the ultimate power when it comes to the system architecture. This is the person called upon to solve the really complex problems. Usually the most talented person that codes for the hardest problems, but overall probably writes the least amount of code on the project. This sometimes isn’t by choice. A lot of the time it is due to the fact that this person is usually in charge of peer code reviews and other administrative duties. Especially duties of discovery and helping find all of the functional requirements. The architect also weighs the risks of implementing new technologies into the system. This person usually has the last call on what technologies go into the system, and what is left out.
The Project Manager
The PM is the person usually in charge of documentation and collaboration. Documenting the current processes through the discovery phase and then working with whom ever they need to to make a functional requirements document out of it. The PM does a lot of system testing to make sure everything passes to spec. The keep a constant watch over the project and budget to make sure that the client stays happy and the project comes in on budget.
The Decision
Starting out as a coder, you usually climb up the latter to a PM or an Architect. If you are in an unfortunate situation then sometimes you have to do it all. Depending on the type of person you are and your desires as a professional, you will choose different paths out of the coder role. I myself am finding that I’m having a hard time with the PM duties because I like to stay more on the technical side of things. I’m not sure if that may change in the future, but for now my next move up is most likely looking to be an Architect.
Conclusion
There comes a point in time as a coder where you will need to make a decision on which way is up. This decision will be made not only for career advancement, but also for some extra padding in the salary department. When that time comes you may be asked to try some things out that you may or may not love. I suggest you give it a good shot because you never know, some things might grow on you.
I recently canceled my account for a VPS in lieu of shared hosting. I was dropping a bunch of websites and didn’t really need a VPS anymore. So I figured I hadn’t touched my website in a while so I thought I’d kick it back up a notch. Aside from a domain name change (major SEO foul, I know), I also decided on a software change for managing my website.
BlogEngine.NET
I was using BlogEngine.NET as my blog software. It actually worked really well, I had no real complaints. The only thing for me was that it wasn’t easily customized. By easy I mean pure and simple customizations. I was on a previous version of it because I hadn’t touched the site in a while, so I’m not sure if this has change or how much in later releases.
Orchard
I chose to go with the Orchard software for my new site. It is full featured and is very easily customized with modules and theme. It’s taken some getting use to, but everything I need to learn is pretty much in the Dashboard of Orchard. There are quite a few articles out there on getting started with Orchard, but a series I found particularly helpful was written by John Papa. You can find it here: http://johnpapa.net/orchardpart1
I’m thinking it will be a bit of an adventure still getting into this. The export and import of my blog worked out nicely. So from here on in, it’s Orchard or bust!
So, I have written before about how to put your database into version control using database projects in Visual Studio. Even while having the scripts in the solution, there can be times when you can’t exactly remember what you changed and needs to go out with your project deployment to the production database. Deploying files is easy because of tools like WinMerge, however deploying things to a database can get quite complicated. You could script both schemas and use WinMerge to see the differences between the development database and the production database. But even doing that, you will still have to write a custom script to get the production database schema up to date.
Enter xSql
xSQLSoftware This is where a tool such as xSQL Object can be extremely helpful. All that need be done is set up the connections, run the comparison, and then you can visually see what has changed between your development and live databases! No need to remember what you changed or any of that, just run the comparison and execute the change script. It will even allow you to save database snapshots before running your change scripts. You can see an excellent walkthroughhere. xSQL Object also comes in a bundle with another one of their products, xSQL Data or by it’s self. xSQL Data allows you to compare data differences between two databases.
The Best Part
All the goodness of the xSQL Bundle (xSQL Object and xSQL Data) Lite Edition comes at a very affordable price FREE! If you only use SQL express edition then you can get the full bundle lite edition and it will work without any restrictions at all! However, if you need to use it against other versions of SQL Server it does have the following limitations:
up to 25 tables
up to 40 views
up to 40 stored procedures
up to 40 functions
If you are using it against a small database then you shouldn’t have any problems. Now if you have databases larger than this and are using SQL Server editions other than express, the product costs $399.00 for a single user license. BUT, after downloading it I was sent an email offering 30% off if I purchased the product within 7 days of the download. That brings the cost down to $280! Not too bad when you compare it with the prices of other comparable tools. So I ask you to go to the website and check it out if you haven’t already! http://www.xsqlsoftware.com
Update
After contacting the company about licensing, I was shown another one of their great tools. A little while back I wrote a post titled Finding Text in SQL Server Stored Procedures. They have a tool called xSQL Object Search that allows you to search for all object types, through the names and definitions, for strings. It will also do a search using regular expressions! Pretty powerful stuff for a **FREE **tool! Check it out here: xSQL Object Search
So you may have found yourself in a similar situation, needing to make a TCP/IP request to a 3rd party API possibly using SSL. Well, that is a quite simple task. It can however, be complicated if this 3rd party requires the use of certificates for communication to its API server. I found myself in some sort of certificate hell where I had the certificate, added it to the request and somehow it still wasn’t working. If you know what I’m talking about and had as many hurdles as I did, my condolences to you. I will try to explain in this article how I started, the problems I ran into and then the overall solution that ended up working for me.
To start with, you should have some kind of certificate. Most likely a *.pfx or *.p12 file. This can also come with a private key or password for the certificate’s encryption. This is what a standard WebRequest over SSL might look like:
publicstringGetData(string inputData) { //will hold the result string result = string.Empty; //build the request object HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://someapi.com/"); //write the input data (aka post) to a byte array byte[] requestBytes = new ASCIIEncoding().GetBytes(inputData); //get the request stream to write the post to Stream requestStream = request.GetRequestStream(); //write the post to the request stream requestStream.Write(requestBytes, 0, requestBytes.Length); //build a response object to hold the response //submit the request by calling get response HttpWebResponse response = (HttpWebResponse)request.GetResponse(); //get the response stream to read the response from Stream responseStream = response.GetResponseStream(); //now read it out to our result using (StreamReader rdr = new StreamReader(responseStream)) { //set the result to the contents of the stream result = rdr.ReadToEnd(); } //return return result; }
The example above is missing the portion where you add the certificate to the request. You may receive a 403 Forbidden error from the server if a certificate is required to make the request to the API server. A simple way of adding a certificate to the request would be like so:
1 2
//add certificate to the request request.ClientCertificates.Add(new X509Certificate(@"C:\certs\Some Cert.p12", @"SecretP@$$w0rd"));
The X509Certificate class is found in the System.Security.Cryptography.X509Certificates namespace. Simply add a new certificate to the client certificates before calling for the response, and it should be sent with the request. However, you may encounter an exception with the message “The system cannot find the file specified”. I encountered this error after I got the application off my local machine and onto the development server. After doing some research I stumbled upon this kb article. This article opened my eyes to how using certificates is a little more complicated than I initially thought. Turns out the problem was that the user trying to access the certificate does not have a profile loaded.
After stepping through the article, installing the certificate to the local machine’s personal certificate store, and then granting rights to the certificate using the WinHttpCertCfg.exe tool, and putting in a little more code found in the kb article, I was well on my way. The article describes how to use C# to open a certificate store and use the certificate directly out of the store. This presents a bit more elegant, and in my opinion more secure, way of getting to and using the certificate.
1 2 3 4 5 6
//add it in a better way X509Store certStore = new X509Store("My", StoreLocation.LocalMachine); certStore.Open(OpenFlags.ReadOnly | OpenFlags.OpenExistingOnly); X509Certificate2 cert = certStore.Certificates.Find(X509FindType.FindBySubjectName, "My cert subject", false)[0]; certStore.Close(); request.ClientCertificates.Add(cert);
This method will not only give access to the certificate regardless of having a loaded profile, but it also takes the certificate’s private key password out of the code and/or configuration. This snippet above took me out of the certificate hell that was crushing my life for a couple days!
publicstringGetData(string inputData) { //will hold the result string result = string.Empty; //build the request object HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://someapi.com/"); //add certificate to the request //request.ClientCertificates.Add(new X509Certificate(@"C:\certs\Some Cert.p12", @"SecretP@$$w0rd")); //add it in a better way X509Store certStore = new X509Store("My", StoreLocation.LocalMachine); certStore.Open(OpenFlags.ReadOnly | OpenFlags.OpenExistingOnly); X509Certificate2 cert = certStore.Certificates.Find(X509FindType.FindBySubjectName, "My cert subject", false)[0]; certStore.Close(); request.ClientCertificates.Add(cert); //write the input data (aka post) to a byte array byte[] requestBytes = new ASCIIEncoding().GetBytes(inputData); //get the request stream to write the post to Stream requestStream = request.GetRequestStream(); //write the post to the request stream requestStream.Write(requestBytes, 0, requestBytes.Length); //build a response object to hold the response //submit the request by calling get response HttpWebResponse response = (HttpWebResponse)request.GetResponse(); //get the response stream to read the response from Stream responseStream = response.GetResponseStream(); //now read it out to our result using (StreamReader rdr = new StreamReader(responseStream)) { //set the result to the contents of the stream result = rdr.ReadToEnd(); } //return return result; }
So, I’m sure you have been met with a similar scenario during development. You know the one that you have to rename a column or even drop a column in the database. This can be quite annoying if you are doing stored procedure based data access for your application. Once you change the column on the table, you have to figure out which stored procedures reference the column. They aren’t always tough to find most of the time, but sometimes you are dealing with a column that may be referenced in many stored procedures. Well thanks to my boss Cliff’s research and knowledge sharing, your search can be as easy as ours!
The query:
1 2 3 4 5 6 7 8 9 10 11
USE Northwind GO DECLARE@SearchTextASVARCHAR(50) SET@SearchText='CustomerID'
SELECT ROUTINE_NAME, ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_NAME LIKE'%'+@SearchText+'%' OR ROUTINE_DEFINITION LIKE'%'+@SearchText+'%'
This query will return all the names and routine definitions of stored procedures that contain certain text. It is not really bound by column names but I needed a true development scenario. Run the query with what you are looking for and presto! All the stored procedures you will need to modify.
So this is what it has come to anymore. Everyone is all about server side paging via SQL Server. As well they should be! It is so much faster and more efficient than having ADO or ADO.NET bring back a ton of records and then chop it to page it. However, there has always been some problems when trying to accomplish this task, especially using a SQL database that is pre 2005.
This task is easier to accomplish in SQL 2005 and 2008 using the ROW_NUMBER() function. The part that gets flaky is having a dynamic order by clause in your SQL statement. Unfortunately, the only way to accomplish this is to write some dynamic SQL. In doing so, It can be hard to tell if the order by parameter received by the stored procedure is a valid one for the table you are selecting from.
Solution
Enter the "IsValidOrderBy" user-defined function. This is a little function that will tell you if the column and order in the dynamic order by parameter is a valid one for the select statement you are running.
CREATEFUNCTION [dbo].[udf_OrderByExists] ( @TableName NVARCHAR(50), @OrderBy NVARCHAR(50) ) RETURNS BIT AS BEGIN DECLARE@Result BIT SET@Result=0 DECLARE@TableColumnsTABLE ( [ColumnNameAndSort] NVARCHAR(100) NOT NULL ) INSERT INTO@TableColumns SELECT [Name] FROM syscolumns WHERE ID = OBJECT_ID(@TableName) INSERT INTO@TableColumns SELECT [Name] +' ASC' FROM syscolumns WHERE ID = OBJECT_ID(@TableName) INSERT INTO@TableColumns SELECT [Name] +' DESC' FROM syscolumns WHERE ID = OBJECT_ID(@TableName) IF EXISTS(SELECT [ColumnNameAndSort] FROM @TableColumnsWHERE [ColumnNameAndSort] =@OrderBy) SET@Result=1 RETURN@Result END
Here you can see that we are taking 2 inputs. The first one being the table name you are selecting from, and the second being the order by clause received by the stored procedure. The function will then return a bit telling you if the column and order was found for the table you are selecting from.
Example
A simple example of using this user defined function would be selecting from a table of products. In that case, your stored procedure could look like so
CREATEPROCEDURE [dbo].[usp_GetProductsPaged] @SortExpression NVARCHAR(50), @PageIndexINT, @PageSizeINT AS -- SET NOCOUNT ON added to prevent extra result sets from -- interfering with SELECT statements. SET NOCOUNT ON; IF ((SELECT [dbo].[udf_OrderByExists]('dbo.Products', @SortExpression)) =0) SET@SortExpression='Name' DECLARE@sqlAS NVARCHAR(MAX), @ParamDefinitionAS NVARCHAR(MAX), @StartRowIndexINT, @RecordCountINT SELECT@RecordCount=COUNT([ProductID]) FROM [Products] IF @PageIndex=0 SET@PageIndex=1 IF @PageSize=0 SET@PageSize=@RecordCount SET@StartRowIndex= ((@PageIndex*@PageSize) -@PageSize) +1 SET@ParamDefinition= N'@paramStartRowIndex INT, @paramPageSize INT' SET@sql= N'SELECT [ProductID], [Name], [Description], [Price] FROM (SELECT [ProductID], [Name], [Description], [Price], ROW_NUMBER() OVER(ORDER BY '+@SortExpression+') AS [RowNumber] FROM [Products]) AS [Prods] WHERE [RowNumber] BETWEEN @paramStartRowIndex AND (@paramStartRowIndex + @paramPageSize) - 1' -- For testing --PRINT @sql --PRINT @StartRowIndex EXEC sp_executesql @sql, @ParamDefinition, @paramStartRowIndex=@StartRowIndex, @paramPageSize=@PageSize SELECT@RecordCountAS [RecordCount]
As you can see, by calling **udf_OrderByExists **and passing in the parameters, if the order by does not fit the table, we then change it to be something known and valid.
Conclusion
With a simple and portable user defined function, we can ensure that the order by clauses going into our paging stored procedures are validated thus keeping integrity. It isn’t fun having to write and maintain dynamic SQL in stored procedures, but it can be done and also made a little bit safer. One last tip: Always use the sp_executesql, as this will tell the SQL server that the execution plan should be cached for re-use.
If you look up accessibility levels on the MSDN web site, it will tell you that the accessibility of the private access modifier is limited to the containing type. I ran into an instance that showed me the direct meaning of this statement. The scenario I had was this: I wanted to have the ability to make an object read only. That is the original object however, if a clone was made then the object could be modified again because it wasn’t the original object. Of course this is a simple task, we get to go back and visit my good friend ICloneable.
So we start off by making our data object, putting in the ability to mark it read only and giving it the ability to clone itself.
Take a look at line #43 above. During the cloning process, you can set the private variable _isReadOnly on the newly cloned object!
For some reason, I was under the impression that any and all private fields and methods were private to that instance of the object. This would mean that all private members of the cloned object would have to be called in the cloned object. To my surprise, this is not the case at all. After changing the _isReadOnly field of the cloned object, the object that was cloned will still remain read only. The cloned object will remain editable until the MakeReadOnly() method is called on it.
Conclusion
All fields and methods with the private access modifier are exposed at any time as long as you are in the containing type. The implications of this are that if you clone an object you will have access to the private members of the newly created object. This can be extremely useful, especially if you want a specific action to be performed on a cloned object but you don’t want to explicitly call that action publicly.